Evaluation¶
在一个 12 核处理器、32GB 内存的单台台式机上,全面测试了 SERENADE 仿真器的各项性能,并与其他现有系统进行了对比,最后通过几个具体的案例展示了其作为数字孪生的能力
5.1 Scalability¶
本小节从“节点数量”和“总体流量”两个维度测试了 SERENADE 的单机扩展极限,并与基线模型进行了对比
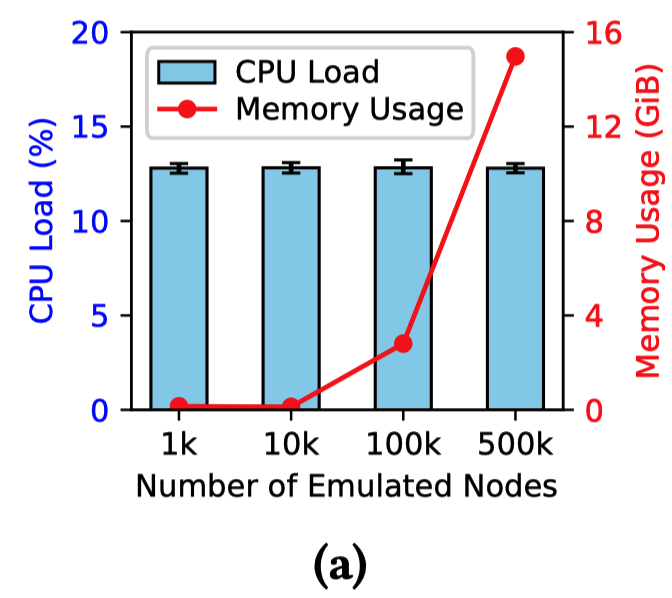
(1) 节点规模的扩展 (Scaling the Nodes):
- 当仅增加非发包节点(闲置卫星、网关、用户)的数量时,CPU 负载几乎保持不变,而内存占用随节点数量线性增长
- 在测试最高达 50万 个节点时,内存占用约为 15 GiB,这是硬件资源带来的主要限制
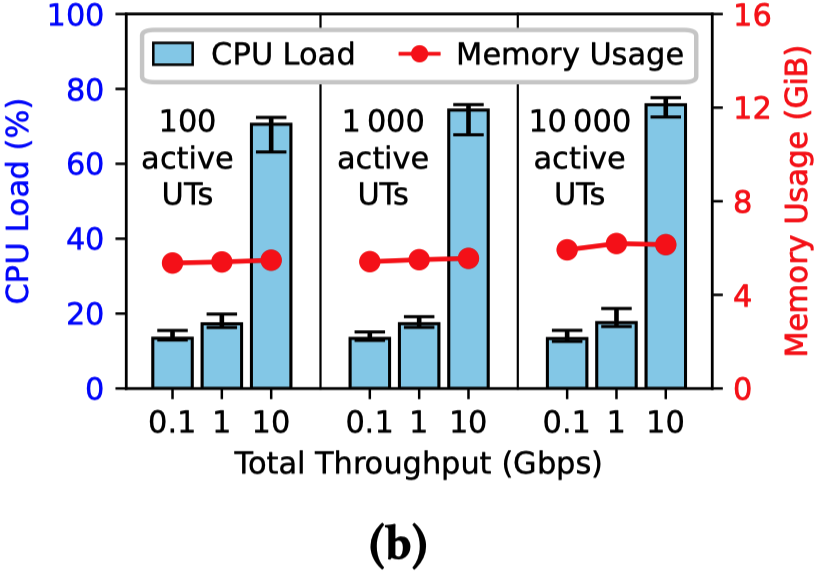
(2) 流量规模的扩展 (Scaling the Traffic):
在总吞吐量相同的情况下(例如总计 1 Gbps),无论活跃用户数是 100 还是 10,000,内存和 CPU 的占用几乎相同
但随着“总体吞吐量”的增加,CPU 负载会显著上升,当总吞吐量达到约 10 Gbps 时(CPU 负载约 75%),CPU 成为主要瓶颈
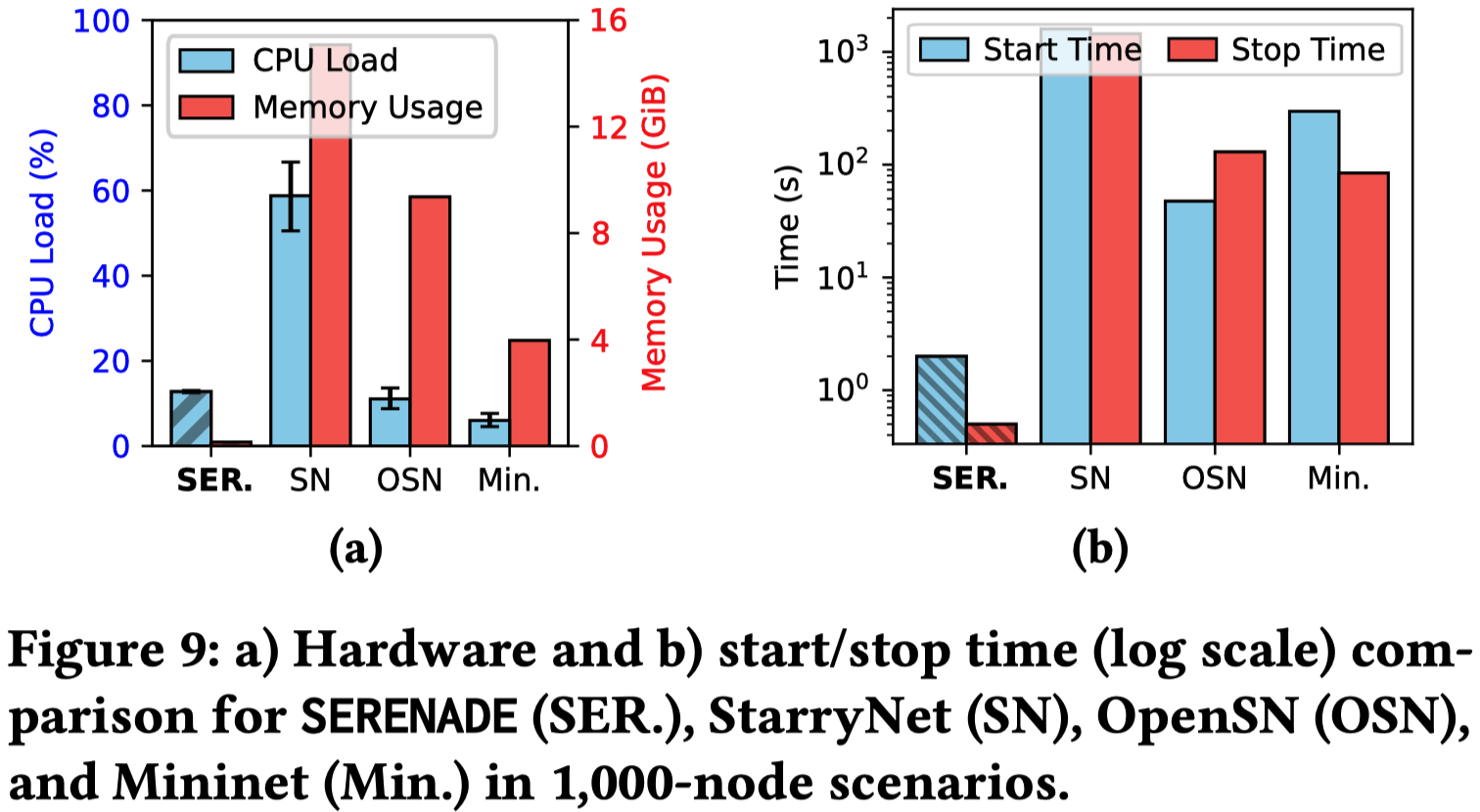
(3) 资源与启动效率对比 (Remaining Efficient):
在 1000 个节点的规模下,与 StarryNet、OpenSN 和 Mininet 相比,SERENADE 的 CPU 和内存占用均为最低
更关键的是,StarryNet 的启动/停止时间长达数十分钟,而 SERENADE 几乎是瞬时(亚秒级)完成启动和拆除
5.2 Networking Realism¶
本小节旨在验证 SERENADE 在高规模下是否依然能保持微观网络行为(如延迟、抖动)的准确性。
(1) 匹配真实世界的延迟 (Matching Real-World Latency):
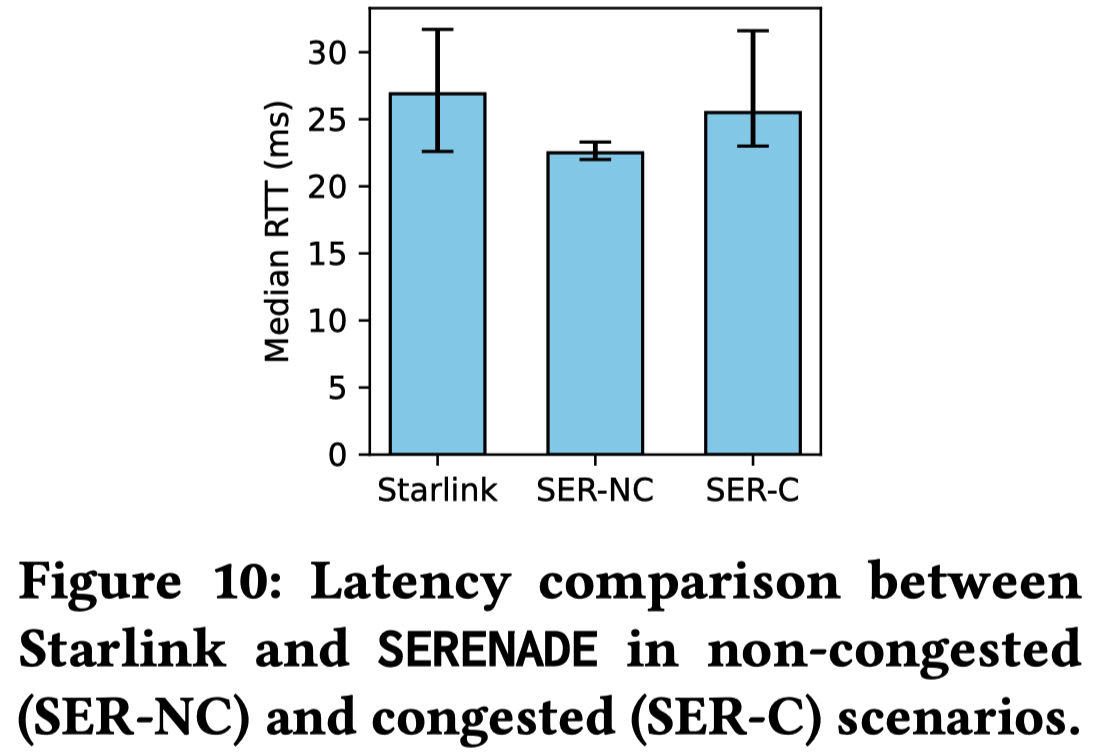
作者利用真实的 Starlink 终端收集了 RTT(往返时间)数据,并与仿真器的数据进行对比
由于 SERENADE 的混合流量模型引入了真实的排队竞争,在拥塞配置下(SER-C),仿真器的延迟分布和波动方差极其完美地贴合了真实 Starlink 网络的测量结果
(2) 高频更新对仿真器延迟的意义 (Emulator Latency):
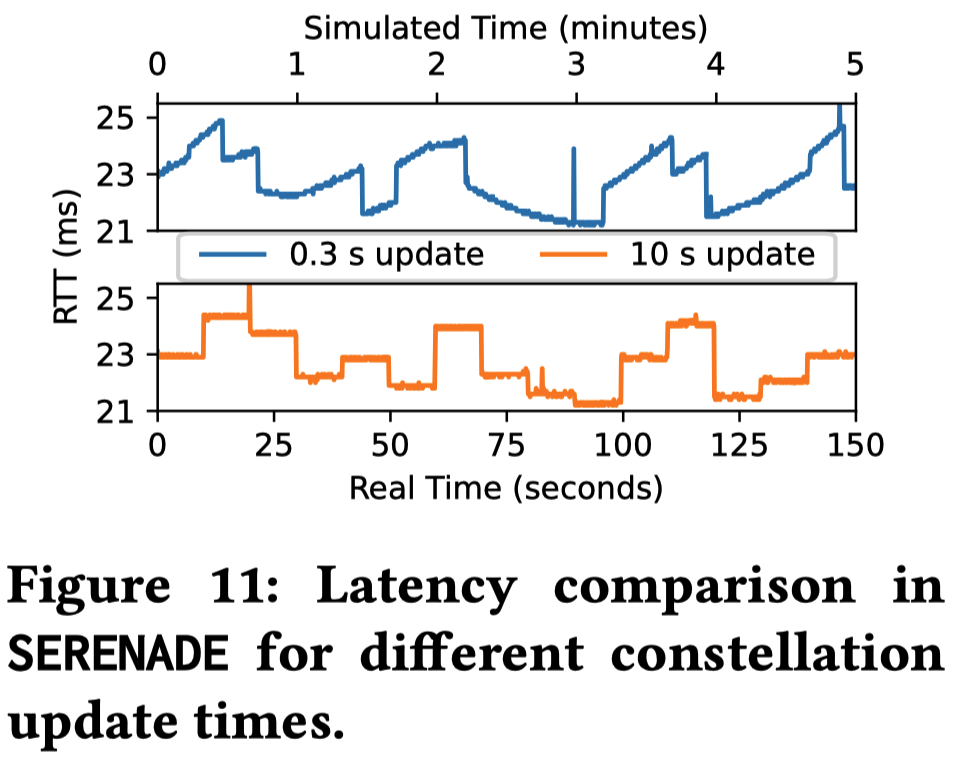
比较了 0.3 秒和 10 秒两次星座状态更新间隔的区别
- 在 0.3 秒的更新频率下,仿真器能够平滑地捕捉到卫星飞越用户头顶时产生的经典“U型” RTT 变化曲线
- 如果更新太慢(如 10 秒),曲线将变成阶梯状,掩盖了真实的延迟动态
(3) 卫星切换下的网络自适应 (Satellite Switches):
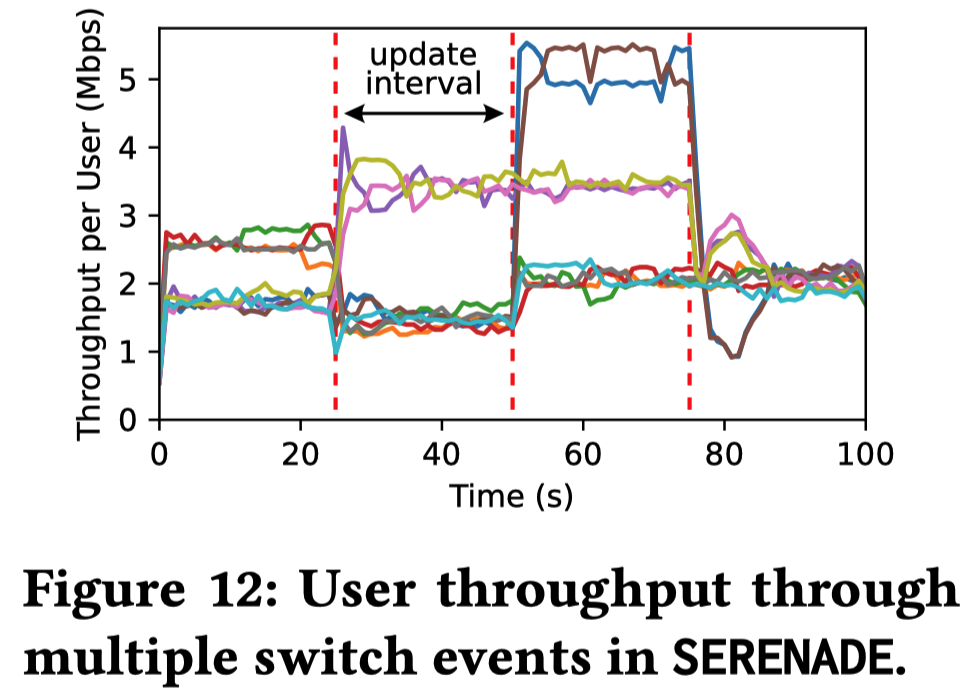
测试了 10 个用户在多颗卫星间切换时的吞吐量表现
当卫星动态离开、加入或改变用户分配时,底层真实的 TCP 流能够精确地根据当前卫星的可用容量(10 Mbps 分摊)自适应调整吞吐量
5.3 Case Study: Network Utilization at Scale¶
连接策略的全局效应
展示了只有在大规模仿真中才能被观测到的网络全局效应。
实验在全美分布了 5000 个用户和 54 个网关,测试了三种网络连接编排策略: 贪心策略(连最近的卫星)、最优规划(Optimized)和图神经网络(GNN)
结果表明:
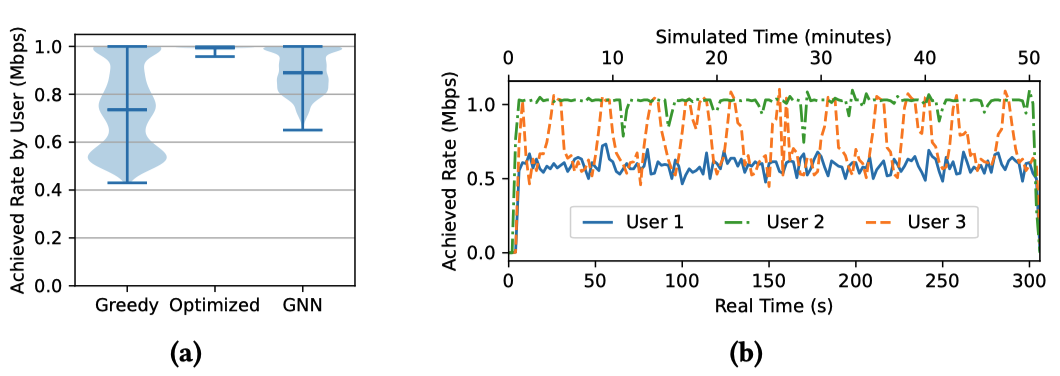
- 采用传统的贪心策略会导致严重的网络拥塞和资源分配不均,用户吞吐量出现明显的“三极分化”(满速、0.75Mbps、0.55Mbps)
- 最优策略完美均衡了负载
- GNN 则在极短的推理时间内达到了接近最优的负载均衡效果
吞吐量分布如 Figure 13a 所示;随机抽取的三个用户的实时吞吐量追踪如 Figure 13b 所示
5.4 Case Study: Responsiveness for Digital Twin¶
实时热更新: 能力 + 作用-现实案例(台风)
展示了 SERENADE 在不中断应用运行的情况下,根据“真实世界”的突发情况 进行实时热更新 的能力
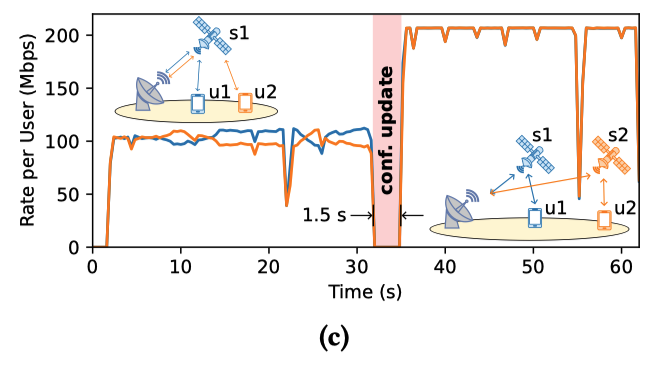
(1) 应对星座更新:
模拟现实中突然增加了一颗新卫星 (s2) 。研究人员可以在“全真”应用流量(iperf 的 TCP BBR 流)不断开的情况下,花约 1.5 秒更新底层系统
更新后,部分用户自动切换到新卫星并独享满速带宽
(2) 应对需求动态:
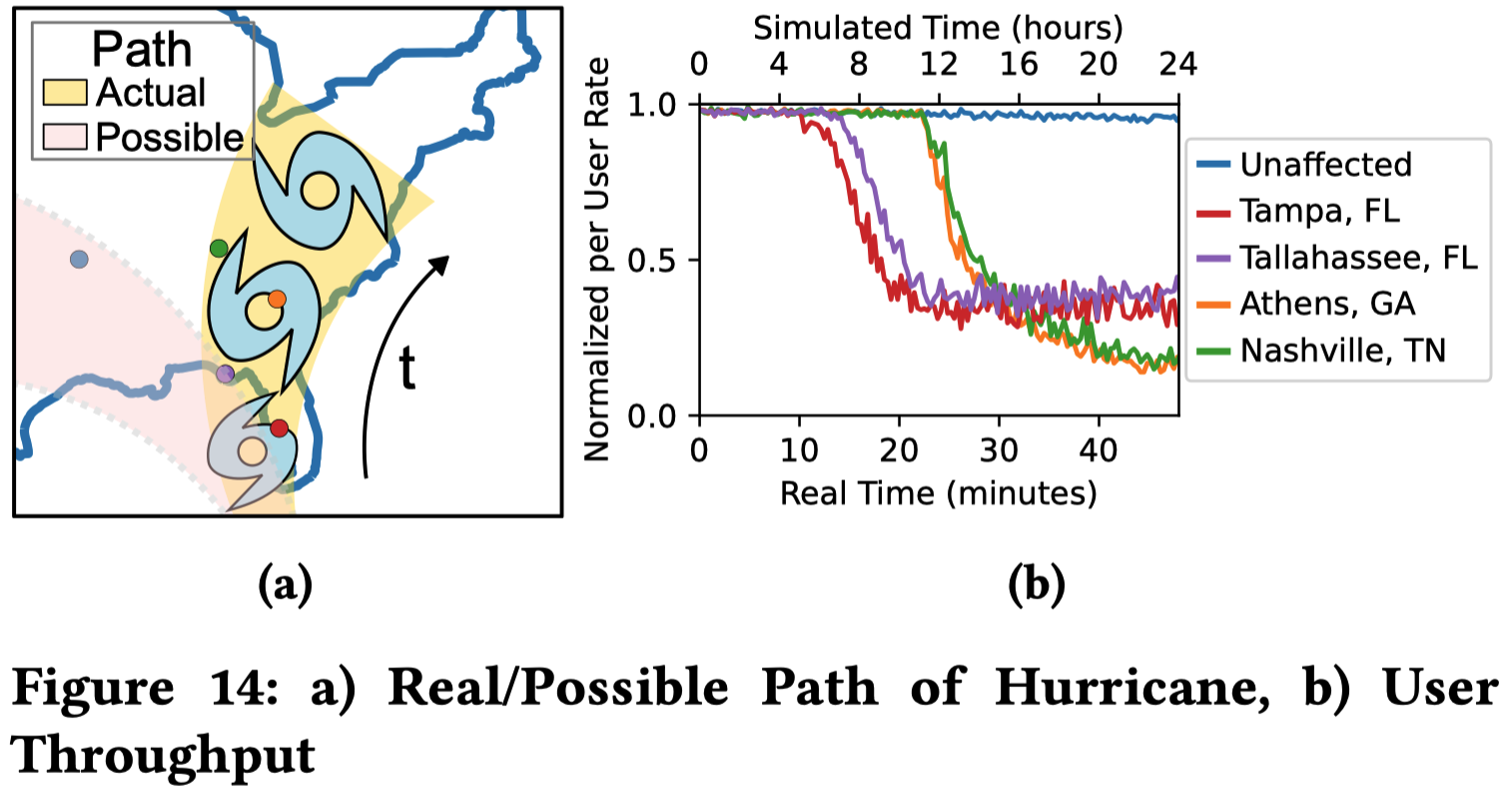
模拟 2024 年飓风海伦摧毁地面基站的场景
在仿真器持续运行期间,当飓风路径确认后,研究人员“动态(on-the-fly)”将受灾路径上综合用户的网络需求提高了 10 倍,以模拟人们涌向卫星网络求救的场景
可以清晰观察到受灾区域用户吞吐量的锐减,而未受影响区域的用户保持正常