MegaStation: Building massive MIMO baseband processing on a single-node supercomputer¶
AI 先读一遍:
-
研究背景:
- Massive MIMO 技术与虚拟化无线接入网 (vRAN) 的结合对基带处理提出了前所未有的极高计算需求,而现有的 vRAN 硬件基础架构很难满足这一需求
-
计算平台:
- 论文提出使用“单节点超级计算机” (Single-Node Supercomputer, SNC) 作为新兴计算平台,该平台通过可组合的 GPU 资源池提供可扩展的计算和通信能力
-
核心挑战:
- 软件处理流水线在不同阶段(如天线、用户和子载波级别)存在不同的执行粒度和不一致的并行度,这与运行时底层动态且不规则的硬件并行性之间存在严重错位
-
解决方案 (MegaStation):
- 作者设计了 MegaStation,这是一个应用程序与平台协同设计的系统,能够有效地利用 SNC 的计算能力来处理 Massive MIMO 基带
-
核心创新:
- 系统将单节点超级计算机建模为一个紧密耦合的微处理器,采用类似计算机体系结构中的记分板 (Scoreboarding) 算法,实时监控硬件并行状态,并动态地在 GPU 执行器上调度“基带处理指令”
-
系统架构:
- MegaStation 包含四个主要软件模块:负责指令翻译和依赖分析的指令单元、在 GPU 上运行的处理功能单元(执行器)、记录硬件状态和指令生命周期的记分板,以及使用创新 LROC 算法的流水线调度器
Abstract¶
-
背景与面临的挑战
- 大规模多输入多输出(Massive MIMO)技术的部署与虚拟化无线接入网(vRAN)的广泛采用,对基带处理提出了极高的计算需求
- 而现有的 vRAN 硬件基础架构很难满足这一需求
-
新兴平台的潜力与痛点:
- 单节点超级计算机(Single-node supercomputer)提供了可扩展的计算和通信能力,是承载基带处理流水线的理想目标
- 然而,实现这一目标十分困难,主要因为软件处理流水线(执行粒度多样且各阶段并行度不一致)与运行时底层动态且不规则的硬件并行性之间存在严重错位
-
提出的解决方案:MegaStation
- 一个应用程序与平台协同设计的系统,旨在有效利用单节点超级计算机的强大算力来处理大规模 MIMO 基带信号
-
核心洞见与技术创新
- 动态调整与重构: 系统的核心理念是,能够根据实时监控到的硬件并行状态,在运行中动态调整执行粒度并重构基带处理流水线
- 体系结构级别的调度映射: 受计算机体系结构中“动态指令调度”的启发,MegaStation 将整个单节点超级计算机建模为一个紧密耦合的微处理器 。
- 记分板机制: 系统采用了一种类似“记分板 (Scoreboarding)”的算法,在 GPU 实例化的执行器上统一编排和调度“基带处理指令”
Introduction¶
-
背景:Massive MIMO 与 vRAN 的结合及其挑战
- 大规模多输入多输出(Massive MIMO)是现代 5G 的关键无线技术
- 而虚拟化无线接入网(vRAN)利用通用服务器或可编程加速器取代了传统的专用 RAN 硬件,带来了缓解供应商锁定、降低总拥有成本(TCO)等优势
-
计算挑战
- 由于大规模天线矩阵操作(如 FFT/IFFT、均衡、编解码等)的复杂性
- 以及严苛的单毫秒级处理截止时间
- vRAN 的基带处理面临着前所未有的计算压力,现有硬件底座难以满足
-
现有解决方案的局限性
- 为了应对计算需求,以往的解决方案要么构建机架规模的分布式系统(如 Hydra),要么使用专用加速器平台(如 LuMaMi)
- 分布式方案的缺陷:采用多台服务器会导致成本高昂且占用过多的物理空间,不利于未来电信站点的基础设施建设
- 专用硬件方案的缺陷:基于 FPGA 的系统(如 LuMaMi)缺乏灵活性,在更新 MIMO 设置时需要重新布局和分区
-
新兴计算平台:单节点超级计算机 (SNC)
- 得益于近期的集群互连技术(如 PCIe、UALink),单节点超级计算机 (SNC) 成为备受瞩目的新型平台
- 它由一台主机和可组合的 GPU 资源池构成
- 提供了极高的执行并行度、充足的通信带宽,并支持按需灵活扩展,是运行高并行基带处理的理想目标
-
痛点与错位 (The Mismatch)
- 利用 SNC 进行基带处理的核心难题在于:软件应用并行度与底层硬件计算并行度之间存在严重的“错位”
- MIMO 基带处理流水线的各个阶段具有不同的执行粒度(天线级、子载波级、用户级等)和不一致的并行度
- 如果调度协调不当,会导致底层硬件并行状态变得极不规则,进而引发无线带宽下降、超时违规和资源浪费
-
本文提出的解决方案:MegaStation 及其架构
- 核心思路:借鉴计算机体系结构领域的“动态指令调度”思想,将单节点超级计算机建模为一个紧密耦合的微处理器,使用类似记分板(scoreboarding)的技术,根据 GPU 硬件状态动态重构基带处理流水线
- 四大核心模块:
- (a) 指令单元(翻译帧序列并分析数据依赖和结构冒险)
- (b) 处理功能单元(在 GPU 上运行基带处理指令)
- (c) 记分板(追踪指令执行状态并对 GPU 池进行资源记账)
- (d) 流水线调度器(采用结合多种技术的 LROC 算法编排指令执行)
写作逻辑值得学习
- 背景与问题
- 解决问题面临的挑战
- 为什么现有方案不行
- 我们的解决方案是什么
- 为什么我们的方案行
Background and Motivation¶
2.1 大规模 MIMO 的基带处理¶
Warning
这一节很重要
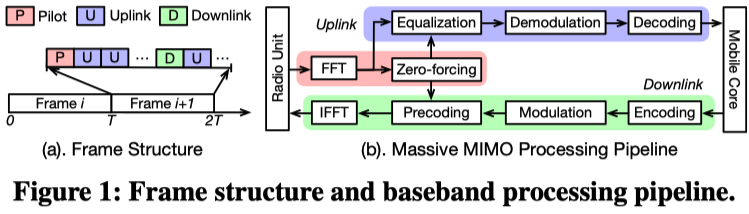
(1) Time Frame:
fig. 1-a
在 Massive MIMO 技术中,多天线无线单元 (RU) 负责接收和数字化信号,并通过前传链路与基带处理单元 (BBU) 交换 IQ 采样数据包
基带处理以时间帧(Time Frame)为单位进行,每个帧包含用于信道估计的导频符号(Pilot symbol)以及承载用户数据的非导频数据符号
(2) 流水线:
fig. 1-b
以 \(M \times K\)(\(K\) 个用户, \(M\) 根天线)的配置为例,BBU 内部包含上行和下行两条处理流水线(如原论文 Figure 1-b 所示),涉及一系列复杂的矩阵操作,例如 FFT/IFFT、迫零 (Zero-forcing, ZF)、均衡、解调以及 LDPC 编解码等
2.2 vRAN 架构下的高计算需求¶
Warning
这一节的 "复杂的并行度冲突" 很重要
vRAN 利用商用服务器或可编程引擎取代了专用硬件,但这给系统带来了巨大的计算压力
压力来自三个方面:
-
复杂的并行度冲突:
- 流水线中各项任务的并行粒度不同(例如: FFT/IFFT依赖天线数量,LB依赖子载波数量,En/Decoding依赖用户数量)
- 导致: 在跨阶段执行时必须进行复杂的数据重排 (Data shuffling)
-
MIMO 规模持续扩张:
- 为了满足未来的通信需求,天线和用户的数量正在不断增加
-
严苛的性能指标:
- 5G 网络要求极高的数据传输速率,且必须满足个位数毫秒级(single-digit millisecond)的超低传输延迟标准
2.3 现有解决方案的局限性¶
-
基于服务器的方案(如 BigStation, Agora, Hydra)
- 这些方案通过分布式多台 PC 来处理流水线,提供了良好的通用计算和可编程性
- 然而,在扩展 MIMO 规模时,它们需要引入更多服务器,导致总拥有成本 (TCO) 过高且占用庞大的物理空间
-
基于硬件加速的方案(如 ASIC BBU, LuMaMi, FlexRAN 等)
- 虽然这类系统在能源和成本效率上表现更好,但严重缺乏可编程性、可操作性和维护性
- 例如,LuMaMi 系统在应对 MIMO 设置变化时,必须重新配置 FPGA 阵列和划分符号处理路径,极其不灵活
2.4 单节点超级计算机¶
得益于新型集群互连技术(如 Routable PCIe 等),基础设施的可组合性成为可能,催生了单节点超级计算机 (SNC) 这一强大的新兴平台
以论文评估所用的 GigaIO FabreX 平台为例。它由一台主机服务器、外部架构交换机以及封装了多个 GPU 的独立机箱组成,通过 PCIe 透明连接:
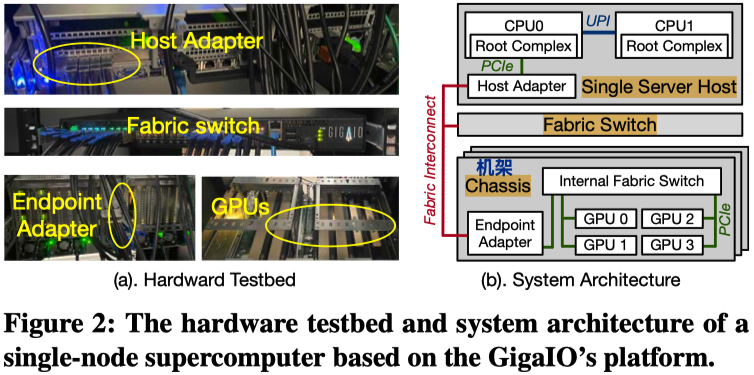
SNC 解决 vRAN 痛点的优势:
-
免除网络开销:每个远程 GPU 在系统中都表现为本地 PCIe 设备
- 避免了传统分布式 GPU 集群必须穿越消息传递层和网络堆栈的通信开销
-
带宽与空间保障:
- 为 Host-GPU 和 GPU-GPU 通信提供了充足的带宽,且物理结构比目前的机架级 vRAN 更紧凑
-
极高灵活性:
- 可通过 PCIe 热插拔机制按需增删 GPU 资源,极大地简化了基础设施规划
Understanding the Execution Parallelism¶
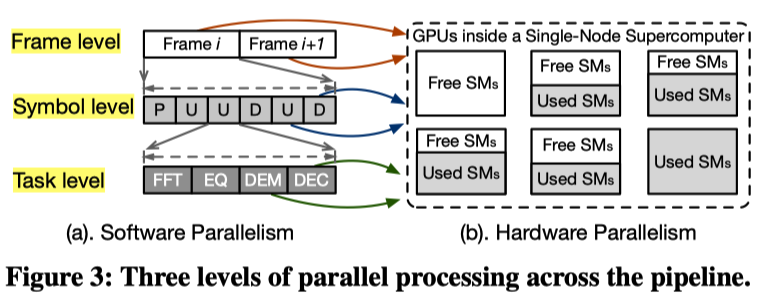
(1) 软件并行性 (SW Parallelism): 基带处理流水线可以通过三种不同的粒度进行并行化
如 fig.3a 所示
- 帧级 (Frame Level):
- 最粗粒度,同时处理连续的多个帧
- 符号级 (Symbol Level):
- 中等粒度,并行处理同一帧内的不同符号(除了必须优先的导频符号)
- 任务级 (Task Level):
- 最细粒度,将具体的处理阶段(如 FFT、均衡等)并行调度,但这会增加同步屏障带来的复杂度
(2) 硬件并行状态 (HW Parallelism):
作者用 GPU 的流多处理器 (SM) 数量来衡量可用硬件并行度, 将其分为四种状态:
如 fig.3b 所示
- 完全并行 (Full):单个 GPU 内有充足的 SM 满足任务需求
- 碎片化并行 (Fragmented):总 SM 足够,但分散在多个 GPU 中,需要跨 GPU 传输数据
- 部分并行 (Partial):SM 总量不足,任务只能获取部分资源,导致性能互相干扰
- 延迟并行 (Delayed):没有空闲 SM,任务必须排队等待
(3) 面临的困境 (The Dilemma):
为了满足 Massive MIMO 的高算力需求,理想情况是充分利用所有粒度的并行
但这种不规则的软件并行,会不可避免地导致底层硬件频繁出现碎片化、部分或延迟并行状态,从而损害系统性能
细致分析见 3.2 / 3.3 / 3.4 章节, 此处不展开
(4) 启示:
- 不存在“一招鲜”的策略:
- 没有任何一种单一的执行粒度(帧级/符号级/任务级)能够完美应对运行中时刻变化的不规则硬件并行状态
- 系统设计启示:
- 理想的基带处理系统必须具备 Execution Adaptive 能力
- 它必须能够感知底层硬件状态的实时变化,并综合考虑后台共同运行的其他内核来进行动态调度
- 这是之前的系统均未能做到的
MegaStation: Design and Implementation¶
(1) Key Idea and System Overview
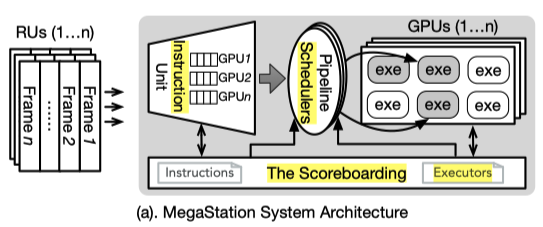
- 核心理念: 系统基于实时监控到的硬件并行状态,在运行中动态调整执行粒度并重构基带处理流水线
- 设计借鉴: 受到动态指令调度的启发,MegaStation 将单节点超级计算机建模为紧密耦合的微处理器,用类似记分板的算法调度 GPU 执行器上的“基带处理指令”
- 四大组件: 系统包含处理功能单元(Executors)、指令单元、记分板和流水线调度器
(2) 细节机制
- 4.2 Baseband Processing Tasks as Instructions: 略过
- 4.3 Baseband Processing Executors over GPUs: 略过
- 4.5 The Scoreboarding: 略过
- 4.6 Pipeline Scheduler: 略过
4.4 Instruction Unit
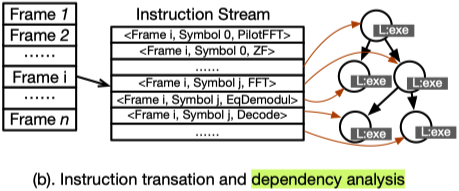
-
三大任务:
- 指令单元接收 IQ 样本后,主要执行: 指令翻译、依赖图(DAG)构建和结构分析
-
依赖与冒险分析:
- 通过分析 "写后读"(RAW) 依赖关系, 构建有向无环图
- 在结构分析中,系统通过估算指令的生命周期,根据目标硬件状态预测来决定指令该去哪个 GPU,并在遇到资源严重短缺(延迟并行)时将指令推入延迟队列
4.7 Deployment and Failure Handling
- 容错设计:借鉴了 Slingshot 的方法
- 把短期丢帧当作无线环境的信号质量衰减来处理,通过蜂窝网络固有的损伤恢复机制来修复
- 故障域响应:
- 系统划分了主机、互连网络和 GPU 池三个故障域
- 主机失效时进入 Fail-stop 模式,丢弃帧并转交备用服务器
- GPU 故障时,驱动程序捕捉异常并将其移出记分板,将未提交的指令送回队列重新调度
- 同时监控守护进程也会随时拉起新接入的可用 GPU 并加入调度
recovering them through inherent cellular network impairments
在传统的计算机分布式系统中,如果一个计算节点(比如这篇论文里的 GPU)崩溃了,系统通常需要极其复杂的容错机制(比如状态机复制、Paxos/Raft 共识算法、检查点备份等)来保证数据不丢失。但这在要求毫秒级延迟的基带处理(vRAN)中是极其昂贵且几乎不可能实现的!
蜂窝网络(如 5G)与有线网络最大的不同在于:无线电波在空气中传输本来就是极不可靠的
在日常生活中,我们的手机信号经常会因为遇到高楼遮挡、天气不好、或者同频干扰而发生“数据包丢失”(这就是所谓 inherent cellular network impairments,即固有的网络物理损伤)。
为了应对这种恶劣的无线环境,4G/5G 协议栈在设计之初,就内置了极其强大的自动纠错和重传机制,例如:
- FEC(前向纠错码):比如论文中提到的 LDPC 码,接收端就算收到了有少量乱码的数据,也能通过算法把正确数据“猜”出来并还原
- HARQ(混合自动重传请求):如果在底层发现某个数据块彻底损坏,基站或手机会立刻在毫秒级内自动请求对方重传
MegaStation 采用的策略就是“搭便车”:
当基带处理过程中发生了计算故障(例如某个 GPU 宕机了,或者算力不够导致某一帧的处理时间超出了 4 毫秒的硬性截止时间),MegaStation 不会去费尽心机地搞复杂的节点恢复,而是直接把这一帧丢弃(Drop)
对于手机端或核心网来说,这看起来就像是“刚才过隧道时信号稍微卡了一下”
随后,5G 协议栈内部的 HARQ 机制会按正常流程自动触发重传。这就巧妙地把服务器的计算容错负担,转移给了无线协议固有的抗干扰纠错机制
我学到了哪些¶
背景知识:
- 单节点超级计算机 (SNC) 构成:
- 1x 主机服务器
- 1x 外部架构交换机
- Nx 封装了多个 GPU 的独立机箱
- 大规模 MIMO 的基带处理:
- 构成: Frame, P, U, D
- 流水线: ...
- 流水线中各项任务的并行粒度不同:
- FFT/IFFT依赖天线数量,LB依赖子载波数量,En/Decoding依赖用户数量
- 导致: 在跨阶段执行时必须进行复杂的 Data shuffling
- 软件并行性:
- Frame-level
- Symbol-level: P, U, D
- Task-level: FFT, EQ, DEC, DEM ...
- 硬件并行性:
- 完全并行 (Full):单个 GPU 内有充足的 SM 满足任务需求
- 碎片化并行 (Fragmented):总 SM 足够,但分散在多个 GPU 中,需要跨 GPU 传输数据
- 部分并行 (Partial):SM 总量不足,任务只能获取部分资源,导致性能互相干扰
- 延迟并行 (Delayed):没有空闲 SM,任务必须排队等待
解法启示:
(1) 通过分析 "写后读"(RAW) 依赖关系, 构建有向无环图
scheduler
(2) 把短期丢帧当作无线环境的信号质量衰减来处理,通过蜂窝网络固有的损伤恢复机制来修复
把服务器的计算容错负担,转移给了无线协议固有的抗干扰纠错机制