SERENADE Emulator Design¶
为了克服现有工具的局限性,我们设计了 SERENADE,这是一种基于线程的低轨卫星网络仿真器,专为满足网络数字孪生系统的需求而构建。
其设计理念以最大化可扩展性、响应能力和真实性为核心,通过消除不必要的抽象层并最小化单节点开销来实现。
与复制完整操作环境的基于容器或微虚拟机的仿真器不同,SERENADE 主要使用 Go 语言编写,并利用超轻量级线程(goroutines)来表示大多数网络节点。这种方法显著降低了每个节点的内存和 CPU 消耗,使得在普通硬件上仿真数十万颗卫星、网关和终端成为可能。
结构性开销的减少 不仅提高了可扩展性,还带来了次生优势:极高的响应能力。
由于摒弃了容器编排、虚拟网络设备管理、进程间通信或内核虚拟化所引入的延迟,SERENADE 能够在几秒钟内初始化、重新配置或拆除大规模网络场景。
与此同时,由于完全基于线程的设计无法在节点中执行任意软件,为了实现网络行为的真实性,SERENADE 引入了一种 混合仿真模型
- 大多数节点被实现为轻量级的线程实体,能够产生合成的背景流量
- 使真实的网络负载、拥塞和竞争模式能够在大规模环境中自然涌现
- 一小部分可配置的节点被实例化为容器化环境(即外部应用模块)
- 能运行未经修改的真实应用程序和协议栈
3.1 Architecture Overview¶
SERENADE 采用模块化架构,将核心仿真功能、星座动态和控制逻辑分离到独立的 Docker 容器中(如图1所示)
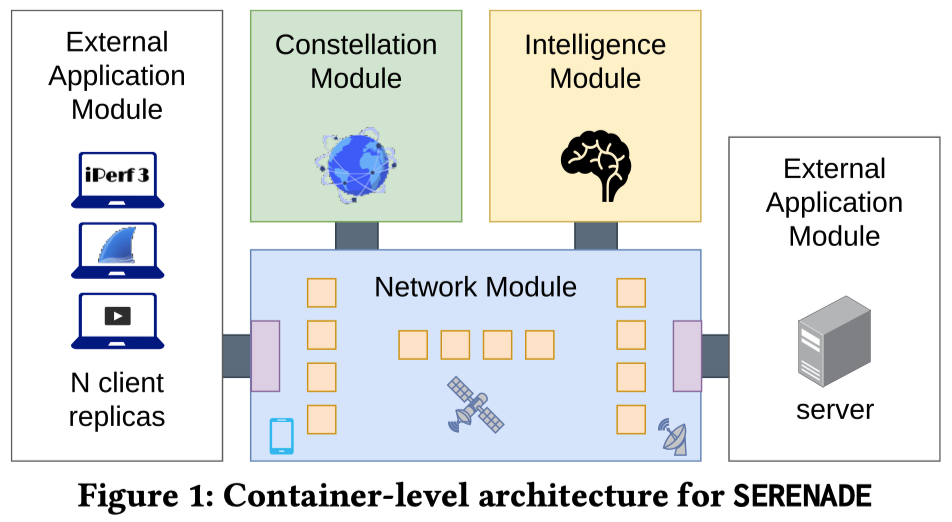
- 网络模块 (Networking Module) 提供核心的数据包转发环境
- 它将卫星、用户终端(UT)和网关(GW)建模为协同工作的轻量级线程组
- 结合了用于模拟真实单向延迟的传播组件,并暴露了连接外部应用程序的接口
- 外部应用模块 (External Application Modules)
- 每一个实例均被实现为一个独立的 Docker 容器,对应特定的 UT 或 GW
- 它们可以运行未经修改的应用程序,并直接与网络模块交互
- 控制平面由星座模块 (Constellation Module) 和智能模块 (Intelligence Module) 组成
- 星座模块使用 Skyfield 定期计算卫星位置,并将其提供给链路状态引擎 (Link State Engine)
- 智能模块则基于这些信息实现灵活的控制平面行为,如用户-卫星关联
3.2 Large-Scale Emulation via Threads¶
SERENADE 的主要设计目标是通过仅实现核心的网络行为(如路由、传输和接收),消除对重量级虚拟化层(如容器、微虚拟机或 Linux 内核网络栈)的依赖,从而最小化单节点开销。
相比之下,轻量级的线程化设计使得 SERENADE 能够在单台机器上扩展至超过 500,000 个节点
在此架构内,网络实体被抽象为一组协同工作的线程,分为三个功能组件:
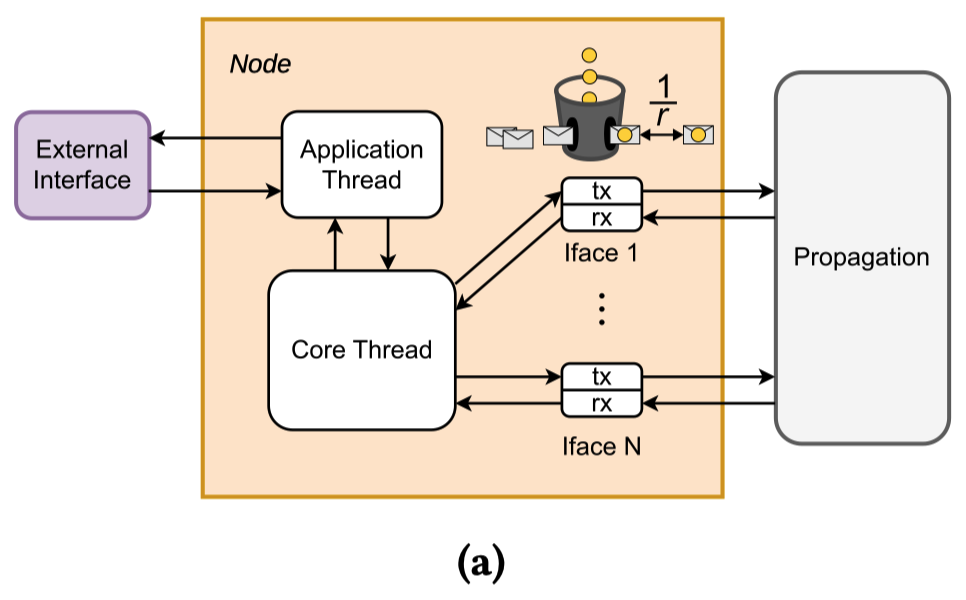
- 核心线程 (Core Thread)
- 应用线程 (Application Thread)
- 发射/接收接口 (Tx/Rx Interfaces)
- 核心线程作为节点的主处理单元,根据控制平面的决策转发数据包
- 应用线程负责处理合成流量或与外部接口交互,同时也具备节点级智能(如处理控制消息)
- 为解决高吞吐量数据包处理的挑战,SERENADE 采用了共享内存传输模型:
- 每个数据包仅被分配一次
- 随后在仿真流水线中通过指针传递"所有权"而非拷贝数据本身进行推进
3.3 Networking Realism in User Space¶
由于 SERENADE 完全在内核之外(用户空间)执行,它无法依赖内置机制来实现精确的计时、排队或速率控制
为此,其设计中融合了多种机制来复现 LEO 通信链路的动态特性
3.3.1 收发器速率 (Transceiver Rates)
每个发射/接收接口由两个专用线程实现,用于执行入口和出口速率限制
由于用户空间调度的非确定性,传统的包间延迟(睡眠指令)难以可靠执行
因此,SERENADE 采用了 "令牌桶 (Token Bucket)" 机制作为速率限制器,这与 Linux 的 tc 流量控制工具行为一致
token bucket
(1) 为什么传统的包间延迟 (Inter-packet delay) 不行?
传统的思路很简单:如果我想控制发送速率为 100 Mbps,那我只要算出每个数据包发送之间应该间隔多长时间(例如 1500 字节的数据包,间隔大概 120 微秒),然后在发包时让程序“睡 (sleep)”这么长时间即可
但这种方法在 用户空间 (User Space) 是不可行的
- 调度的非确定性:在 Linux 系统中,用户态程序的
sleep()指令是不精确的- 当你告诉系统“休眠 120 微秒”时,系统只能保证至少休眠 120 微秒
- 原因: 误差累积:
- 由于 CPU 负载和 Go 运行时的调度,程序可能在 200 微秒甚至 500 微秒后才被唤醒
- 这种不可预测的额外延迟会导致吞吐量严重抖动,根本无法精确控制速率
(2) Token Bucket 机制是如何运作的?
令牌桶(Token Bucket)是一种非常优雅的流量整形(Traffic Shaping)算法,它不依赖于让程序“精准睡眠”,而是通过“记账”的方式来控制平均速率
- 匀速注水(生成令牌):
- 系统以一个恒定的速率(例如每秒 10 MB)向一个“水桶”里放入“令牌 (Token)”
- 这个速率就是你想要限制的 最高平均传输速率
- 桶的容量(突发限制):
- 桶是有大小的,最多只能装固定数量的令牌
- 满了之后,新产生的令牌就会被丢弃
- 这决定了网络允许的最大突发流量
- 按需取水(消耗令牌):
- 当一个数据包准备发送时,它必须从桶里拿走与自己体积等量(或成比例)的令牌
- 如果桶里令牌够:数据包拿走令牌,瞬间发送出去,无需任何等待
- 如果桶里令牌不够:数据包就必须排队等待,直到桶里匀速生成的令牌积攒够了,才能发送
它的优势在于:即使系统调度有轻微延迟,令牌依然在后台稳定积累。下次程序醒来时,桶里攒够了更多的令牌,就可以瞬间连续发好几个包,从而确保宏观上的平均速率是绝对精准的
(3) 这个机制在 Linux tc 中是如何实现的?
tc 中经典的限速模块就是 TBF (Token Bucket Filter)
- 时钟精度的限制:
- 在 Linux 内核中,时钟中断(Clock Interrupt)的最大频率通常是 1 kHz(即 1 毫秒一次)
- 这意味着系统 没法做到 每 1 微秒往桶里放一点令牌,而是 每 1 毫秒往桶里放一大把令牌
- 原理跟上面提及的一样。只有一点细微差异:
- 为了能达到目标速率,
tc必须允许更大的“桶容量”(即允许一定的突发流量) - 当这 1 毫秒积累的令牌发下来时,会瞬间把堆积的包发出去
- 为了能达到目标速率,
SERENADE 因为运行在用户空间,也受到类似 Go 调度精度的影响,因此它采用了与 tc 相同的处理逻辑,其表现出来的流量微观突发特征也与真实的 Linux 网络栈如出一辙
3.3.2 链路信道容量 (Link Channel Capacities)
SERENADE 提供了一种机制,通过调整令牌桶中令牌与数据包的"兑换率",来近似模拟大规模的链路级变化
增加每个数据包所需的令牌数即等效于降低信道容量
默认情况下,信道退化被建模为仰角 \(\theta\) 的函数,计算公式受参数 \(k, \theta_0\) 以及 \(\alpha\) 控制 。当聚合需求超过卫星容量时,一旦缓冲区填满,数据包将按比例被丢弃
3.3.3 传播延迟 (Propagation Delays)
准确仿真传播延迟是一项核心挑战。预分配满足全局聚合带宽延迟乘积(BDP)的内存是不切实际的,BDP 定义为:
为了在极低资源开销下精确仿真延迟,系统引入了"传播模块 (Propagation Module)"
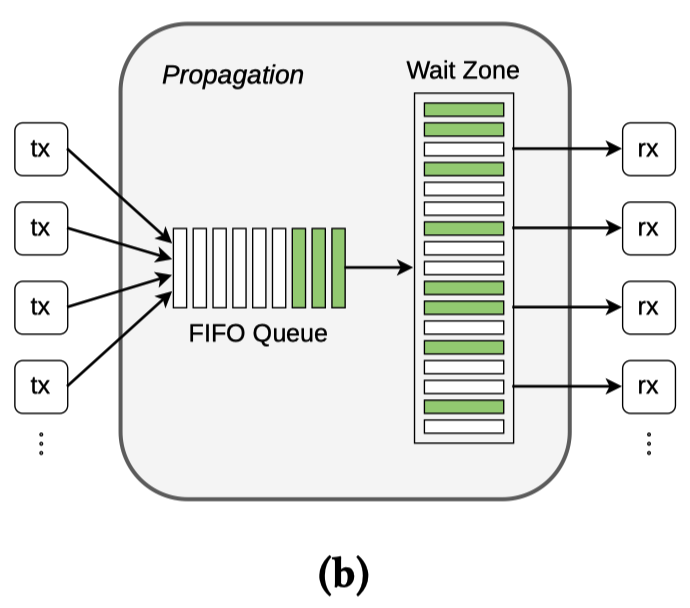
它使用一个 FIFO 队列聚合数据包,并将其送入 "等待区 (Wait Zone)",该区域内的专用线程高频扫描数据包指针数组,当发送方设定的传输时间戳过期时才会释放数据包
wait zone
(1) 为什么需要这个模块?
低轨卫星距离地面很远(数百公里),电磁波传输需要时间,通常会产生几毫秒到十几毫秒的物理传播延迟
- 内存爆炸的风险:
- 在仿真器中,“延迟”一个数据包的唯一方法,就是把它缓存在内存里,等时间到了再交给接收方
- 计算 BDP (带宽延迟乘积):
- 如果一条链路的速度是 1 Gbps,延迟是 10 ms,那么链路上同时“飞在空中”的数据大约有 10 Mb。在拥有几十万个节点的超大规模仿真:\(BDP_{total}=\sum_{\forall i\in A}R_{i}d_{i}\)
- 为网络中每一条 "潜在的GSL和ISL" 都预先分配专门的缓冲队列,会消耗极其庞大的内存,这在单台机器上是不可能的
(2) 这个机制是如何运作的?
为了解决海量链路导致内存耗尽的问题,SERENADE 没有采用“每条链路一个队列”的传统做法,而是设计了一个全局的共享时钟池,也就是你看到的“传播模块”
- 打时间戳:当任何一个节点(无论是终端还是卫星)发送出一个数据包时,它的核心线程(Core Thread)会算好这个包在太空中要飞多久,并在包上贴一个“释放时间戳”
- 汇入总池 (FIFO):所有发出的数据包(其实只传递轻量级的内存指针,不拷贝数据)都会排队进入一个总的 FIFO 队列
- 进入等待区 (Wait Zone):等待区其实就是一个大数组。专用的线程会不断把 FIFO 队列里的数据包填进这个数组的空位里
- 高频轮询扫描:等待区内有一个极其勤奋的专用线程,以极高的频率(大约每 80 微秒一次)疯狂扫描整个数组
- 它每次看到一个包,就对比一下当前时间和包上的“释放时间戳”
- 时间没到?略过,继续扫描下一个
- 时间到了?将这个包“释放”给接收方节点,并清空数组的这个槽位
通过这种设计,几十万个节点不需要维护各自的传播队列,所有“飞在空中”的数据包全都在一个高度优化的数组里被集中管理
3.4 Hybrid Traffic Model¶
SERENADE 的决定性特征是其混合流量模型,使得合成流量和真实流量能够在同一仿真网络中共存并交互
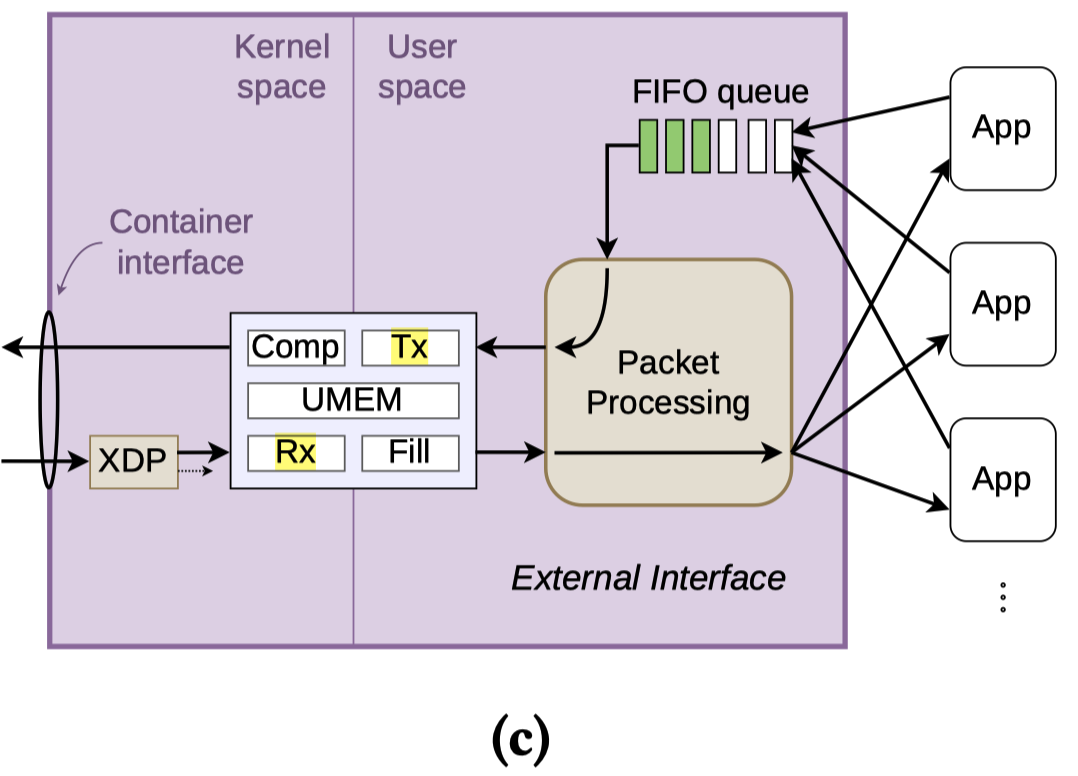
- 合成流量由内部应用线程按配置速率生成,提供代表数千个用户的大规模背景负载
- 真实流量则源自外部应用模块,通过
AF_XDP套接字(绕过内核栈以实现极低延迟通信)注入仿真环境
真实数据包与合成数据包在相同的链路和缓冲区中竞争,自然地重现了真实的拥塞效应和缓冲延迟,无需像传统仿真器那样人为注入延迟
Warning
这一段"虚实结合"很好. 但笔者总感觉它 "bypass" 了两个关键问题:
- 本文(包括后续)有说明最多可以支持多少“全真”吗?
- “合成流量”是如何合成的?我没理解其中的科学性?
(1) 论文本身并没有给出一个明确的“全真节点上限数”:
- 硬件资源瓶颈(CPU 与吞吐量):
- 论文在 5.1 节指出,无论是真实流量还是合成流量,当整个仿真网络上的聚合吞吐量超过 10 Gbps 时,一台 12 核 32GB 的工作站的 CPU 占用率就会达到 75% 左右,成为明显的瓶颈
- 实验中的实际使用量:例如 5.2 节的卫星切换和 5.3 节的网络利用率实验
- 作者通常是在 5000 个合成用户的背景下,抽取 10 个 用户作为“全真”节点,接上外部应用程序(如 iperf)来测量真实吞吐量
结论: "全真"节点的数量受限于宿主机的 Docker 并发能力和总体网络吞吐量
在单台机器上,这个数量大概率在几十到几百个之间。SERENADE 的精妙之处在于:你不需要让所有人都是“全真”的,只需要几个“全真”节点作为探针,其他的用合成流量塞满背景即可
(2) “合成流量”是如何合成的?其中的科学性在哪里
合成流量(Synthetic Traffic)的生成原理很简单:节点内部的 Go 线程根据配置文件中设定的速率,利用前面提到的“令牌桶”机制,源源不断地生成固定或随机大小的“假数据包(Dummy Packets)”发往卫星 。
- 在大规模网络研究中,卫星路由器或网关其实根本不关心你的数据包里装的是视频、网页还是乱码
- 它只关心一件事: 缓冲区(Buffer/Queue)满了没有
- 当成千上万个用户同时向一颗卫星发送数据时,卫星的转发队列会被填满,导致后续到达的数据包排队等待(产生延迟/丢包)
结论: SERENADE 让轻量级线程产生海量的合成包,去“占领”卫星的带宽和缓冲队列
此时,你注入的那个“全真”数据包在排队时,感受到的是和真实世界一模一样的拥塞、排队延迟和抢占压力
这就用极低的算力成本,完美逼真地还原了大规模网络的负载环境
3.5 Satellite Modeling and Control Plane Architecture¶
为了编排动态的卫星网络,SERENADE 的控制平面将轨道传播、节点角色分配和链路状态评估进行了分离:
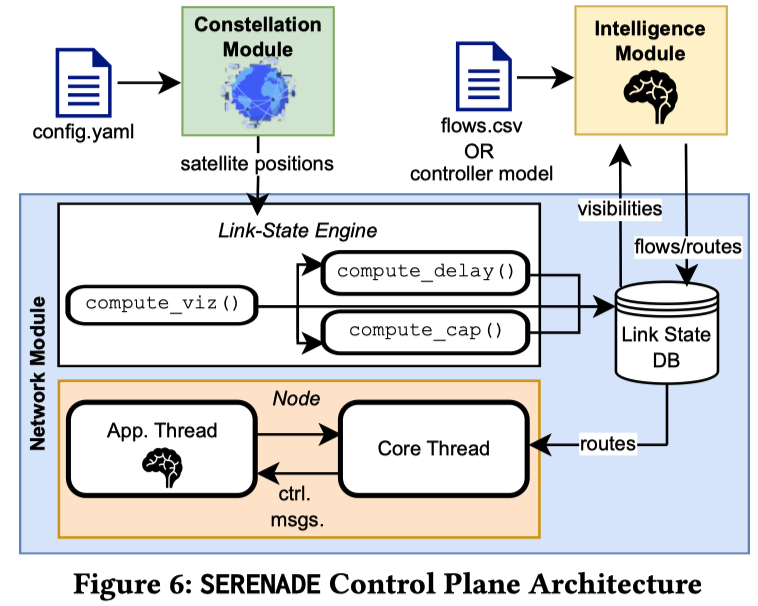
(1) Constellation Module:
使用 Skyfield 按需计算卫星的 ITRF 坐标更新 。系统引入了"时间膨胀因子" \(\eta\),使得时间戳的更新公式为:
这种将星座物理移动与实时流量仿真解耦的设计,允许长期轨道行为(数小时/天)在压缩的几分钟内完成模拟,同时保持实时的数据包级交互
'时间膨胀因子'的意义是什么
这个机制是为了解决一个极其现实的“仿真时间矛盾”:数据包飞得太快,而卫星飞得太慢
- 现实痛点:低轨卫星(如星链)绕地球一圈大约需要 90 分钟
- 如果研究人员想测试“我的路由算法在 24 小时内,随着卫星不断升起、落下、切换,会不会崩溃?”
- 在传统的实时仿真器中,你只能傻傻地开着电脑等上 24 个小时 (NOTE: 笔者对此表示高度存疑)
- 时间膨胀的作用(快进键):论文中给出了公式 \(T[n]=T[n-1]+\Delta t\cdot\eta\)
- 这里的 \(\eta\) 就是时间膨胀因子
- 如果设置 \(\eta = 10\),这意味着现实世界(服务器)过去 1 秒钟,仿真器里的卫星物理位置就已经向前推进了 10 秒钟
- 为何不影响网络真实性?
- SERENADE 将“星座物理移动”和“网络数据包交互”解耦
- 数据包的收发、排队、TCP 拥塞控制,依然是微秒级实时进行的
- 但是天上卫星的移动被按下了“快进键”
在论文 5.3 节的实验中,作者设置 \(\eta = 10\)。他们在物理机上只运行了 300 秒(5分钟),但由于时间膨胀,系统在物理层面上模拟了卫星飞行 50 分钟的轨迹变化
因此该机制的意义是:
允许研究人员在几分钟的真实时间里,观察到网络在数小时甚至数天的宏观轨道变化下是如何演进的,极大地提升了研发和测试的效率
数据包和卫星时间轴解耦的科学性
理解这个机制的关键在于明白:底层的网络协议与组件(TCP/UDP、队列、路由器)根本不知道,也不关心天上的卫星在哪里,它们只关心三个数字:链路连不连得通?延迟是多少?带宽是多少?
(1) 物理世界与网络世界的"翻译官"
在 SERENADE 中,物理时间轴和网络时间轴之所以能协同,是因为中间有一个核心的“翻译官”: 链路状态引擎 (Link-State Engine)
- 物理时间轴(快进):
- 星座模块 (Constellation Module) 负责算天体物理
- 它使用了带有“时间膨胀因子(\(\eta\))”的公式来计算卫星的新坐标
- 如果 \(\eta=10\),物理仿真器就会认为"现实"中的 1 秒等同于"太空"中的 10 秒
- 翻译与同步:
- 一旦坐标算出来,链路状态引擎就会立即计算出此时的卫星可见性、传播延迟和信道容量
- 共享数据库:
- 这些计算出的网络参数会被写入一个所有线程都可以实时访问的共享数据结构中
(2) 网络模块的"毫不知情"
网络模块(发包的那些轻量级线程和真实 Docker 容器)完全运行在现实的 1 倍速时间轴上
- 当一个真实的数据包(比如你的 iperf 测速包)准备发送时,它会去查看那个共享数据库:
- “我现在的延迟是多少?最大速率是多少?”
- 网络线程会严格按照共享数据库里此时此刻的数值,在现实时间中对数据包进行排队、扣除令牌、并计算微秒级的发包动作
(3) 举个例子
假设现实中,一颗卫星飞过你的头顶需要 10 分钟。在这个过程中,物理延迟会平滑地从 15ms 降到 10ms,再升回 15ms
- 当你设置时间膨胀因子为 10 时,在物理坐标计算模块看来,这颗卫星只用了 1 分钟(现实时间)就飞完了全程
- 链路状态引擎会把这个信息翻译成网络参数:
- 在现实的 1 分钟内,共享数据库里的延迟数值从 15ms 快速降到 10ms,再升回 15ms
- 此时,你的电脑正在跑一个真实的 TCP 测速程序(它运行在 1 倍速的现实时间里):
- 对这个 TCP 程序来说,它其实并不知道模拟器被加速了
- 它的直观感受只是: 哇,我连上了一个飞得特别快的卫星!它的物理延迟变化得好快!而且 1 分钟后它就飞走了(发生切换)!
(2) Link-State Engine:
计算可见性、传播延迟和信道容量
该引擎效率极高,例如在 10,000 个地面节点的规模下,更新 1584 颗卫星状态的延迟仅约 340 毫秒,能够支持每秒约 3 次的次秒级星座更新
(3) Intelligence Module & Node-Level Control:
智能模块负责生成复杂的空地关联分配(支持默认贪心算法或集成自定义的路由逻辑)
此外,控制平面功能还可源自节点应用线程内部,例如直接生成控制报文以仿真 3GPP 非地面网络(NTN)中大量的切换信令交互